Jaringan saraf konvolusional digunakan dalam tugas visi komputer yang menggunakan lapisan convolutional untuk mengekstraksi fitur dari data input. Jaringan saraf convolutional (CNN) adalah kelas jaringan saraf dalam yang biasa digunakan dalam tugas visi komputer seperti pengenalan gambar dan video, deteksi objek, dan segmentasi gambar.
Neural network adalah model pembelajaran mesin yang terdiri dari node yang saling berhubungan yang memproses informasi untuk membuat keputusan, sedangkan deep neural network memiliki banyak lapisan tersembunyi yang memungkinkannya mempelajari representasi kompleks untuk berbagai tugas. Keduanya meniru struktur dan fungsi otak manusia. Visi komputer adalah bidang kecerdasan buatan (AI) yang berfokus pada memungkinkan mesin untuk menginterpretasikan dan memahami data visual dari dunia.

Meskipun pengenalan gambar dan video melibatkan pengklasifikasian atau pengenalan objek, adegan, atau tindakan dalam foto atau video, deteksi objek melibatkan penempatan hal-hal tertentu di dalam gambar atau video. Segmentasi gambar melibatkan pembagian gambar menjadi segmen atau wilayah yang bermakna untuk analisis atau manipulasi lebih lanjut.
CNN menggunakan beberapa lapisan konvolusional untuk secara otomatis mengekstraksi fitur dari data masukan. Data input dikenai filter oleh lapisan konvolusional dengan peta fitur yang dihasilkan diteruskan ke lapisan pemrosesan lebih lanjut. Lapisan konvolusional adalah blok bangunan CNN yang melakukan operasi pemfilteran dan ekstraksi fitur pada data masukan.
Filtering adalah proses penggabungan citra dengan filter untuk mengekstrak fitur, sedangkan ekstraksi fitur adalah proses mengidentifikasi pola atau fitur yang relevan dari citra yang digabungkan. Pooling layer yang menurunkan output dari convolutional layer untuk menurunkan biaya komputasi dan meningkatkan kapasitas jaringan untuk menggeneralisasi input baru sering disertakan dalam CNN selain convolutional layer.
Lapisan tipikal tambahan termasuk lapisan normalisasi yang membantu menurunkan overfitting dan meningkatkan kinerja jaringan dan lapisan yang terhubung sepenuhnya yang digunakan untuk tugas klasifikasi atau prediksi. Banyak aplikasi seperti pengenalan wajah, mobil tanpa pengemudi, analisis citra medis, dan pemrosesan bahasa alami (NLP) telah banyak yang menggunakan CNN. Mereka juga telah digunakan untuk mencapai hasil tercanggih dalam tugas klasifikasi gambar seperti tantangan ImageNet.
Bagaimana cara kerja jaringan saraf konvolusional?
Jaringan saraf konvolusional bekerja dengan mengekstraksi fitur dari data input melalui lapisan convolutional dan belajar untuk mengklasifikasikan data input melalui lapisan yang terhubung sepenuhnya. Langkah-langkah yang terlibat dalam kerja jaringan saraf convolutional meliputi:
- Lapisan masukan: Lapisan pertama dalam CNN yang mengambil data mentah sebagai masukan seperti gambar atau video dan mengirimkannya ke lapisan berikutnya untuk diproses.
- Lapisan konvolusional: Ekstraksi fitur terjadi di lapisan konvolusional. Lapisan ini menerapkan kumpulan filter atau kernel untuk mengekstraksi fitur seperti tepi, sudut, dan bentuk dari data masukan.
- Lapisan ReLU: Untuk memberikan non-linearitas ke output dan meningkatkan kinerja jaringan, fungsi aktivasi unit linier yang diperbaiki (ReLU) sering diimplementasikan setelah dan setiap lapisan konvolusional. ReLU mengeluarkan input secara langsung jika positif dan menghasilkan nol jika negatif.
- Pooling layer: Peta fitur convolutional layer dibentuk dengan pooling layer yang mengurangi dimensinya. Max-pooling adalah teknik yang umum digunakan di mana nilai maksimum di setiap tambalan peta fitur diambil sebagai keluaran.
- Fully connected layer: Fully connected layer mengambil output yang diratakan dari pooling layer dan menerapkan serangkaian bobot untuk menghasilkan output akhir yang dapat digunakan untuk tugas klasifikasi atau prediksi.
Berikut adalah ilustrasi bagaimana cara kerja CNN yang mengkategorikan gambar kucing dan anjing:
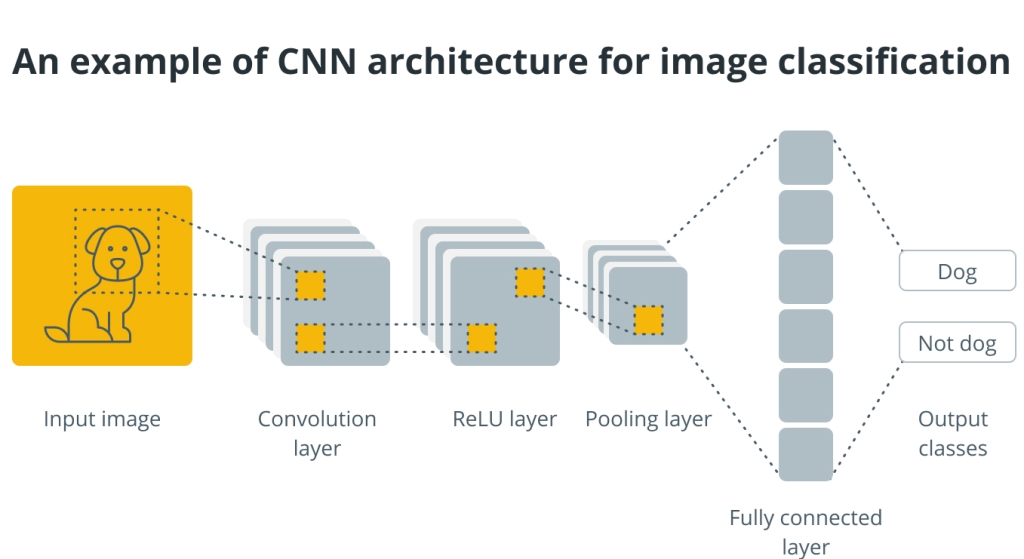
- Langkah 1: Lapisan input menerima gambar anjing atau kucing 3 saluran (RGB) dan data gambar mentah lainnya. 3-saluran (RGB) adalah format standar yang digunakan untuk merepresentasikan gambar berwarna dalam jaringan saraf dengan setiap piksel diwakili oleh tiga nilai yang mewakili intensitas saluran warna merah, hijau, dan biru.
- Langkah 2: Lapisan convolutional menerapkan serangkaian filter ke gambar input untuk mengekstraksi fitur seperti tepi, sudut, dan bentuk.
- Langkah 3: Output lapisan konvolusional menjadi non-linear karena lapisan ReLU.
- Langkah 4: Dengan mengambil nilai maksimum di setiap tambalan peta fitur, lapisan penyatuan menurunkan dimensi peta fitur yang dibuat oleh lapisan konvolusional.
- Langkah 5: Banyak lapisan convolutional dan pooling ditumpuk untuk mengekstraksi karakteristik yang semakin rumit dari gambar masukan.
- Langkah 6: Ratakan lapisan mengubah keluaran lapisan sebelumnya menjadi vektor satu dimensi atau 1D (urutan angka yang disusun dalam satu baris atau kolom, masing-masing mewakili fitur atau karakteristik). Kemudian lapisan yang terhubung sepenuhnya menerima keluaran yang diratakan dari lapisan penyatuan terakhir dan menerapkan serangkaian bobot untuk menghasilkan keluaran akhir yang mengidentifikasi apakah gambar tersebut adalah kucing atau anjing.
CNN dilatih menggunakan sekumpulan gambar berlabel dengan bobot filter dan lapisan yang terhubung sepenuhnya dengan pyenyesuaian selama pelatihan untuk meminimalkan kesalahan antara label yang diprediksi dan sebenarnya. Setelah dilatih, jaringan saraf convolutional dapat secara akurat mengklasifikasikan gambar kucing dan anjing yang baru dan tidak terlihat.
Apa saja jenis jaringan saraf konvolusional?
Ada beberapa jenis jaringan saraf konvolusional, termasuk CNN tradisional, jaringan saraf berulang, jaringan konvolusional penuh, dan jaringan transformator spasial yang dijelaskan dibawah ini:
CNN tradisional
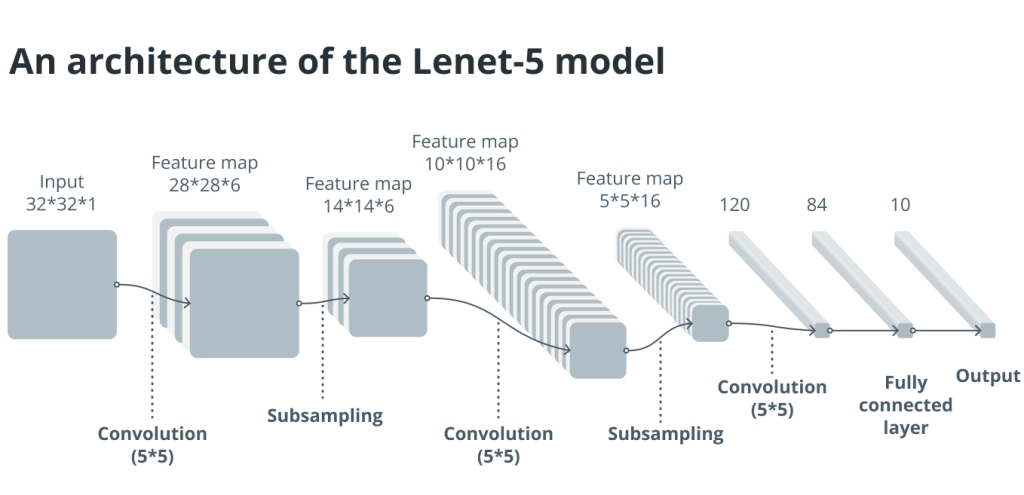
CNN tradisional juga dikenal sebagai CNN “vanilla” yang terdiri dari serangkaian lapisan convolutional dan pooling, diikuti oleh satu atau lebih lapisan yang terhubung sepenuhnya. Seperti disebutkan diatas, setiap lapisan konvolusi dalam jaringan ini menjalankan serangkaian konvolusi dengan kumpulan filter yang dapat diajarkan untuk mengekstraksi fitur dari gambar masukan.
Arsitektur Lenet-5, salah satu CNN efektif pertama untuk pengenalan digit tulisan tangan, mengilustrasikan CNN konvensional. Ini memiliki dua set lapisan convolutional dan pooling mengikuti dua lapisan yang terhubung sepenuhnya. Efisiensi CNN dalam identifikasi gambar dibuktikan dengan arsitektur Lenet-5 yang juga membuatnya lebih banyak digunakan dalam tugas visi komputer.
Jaringan saraf berulang
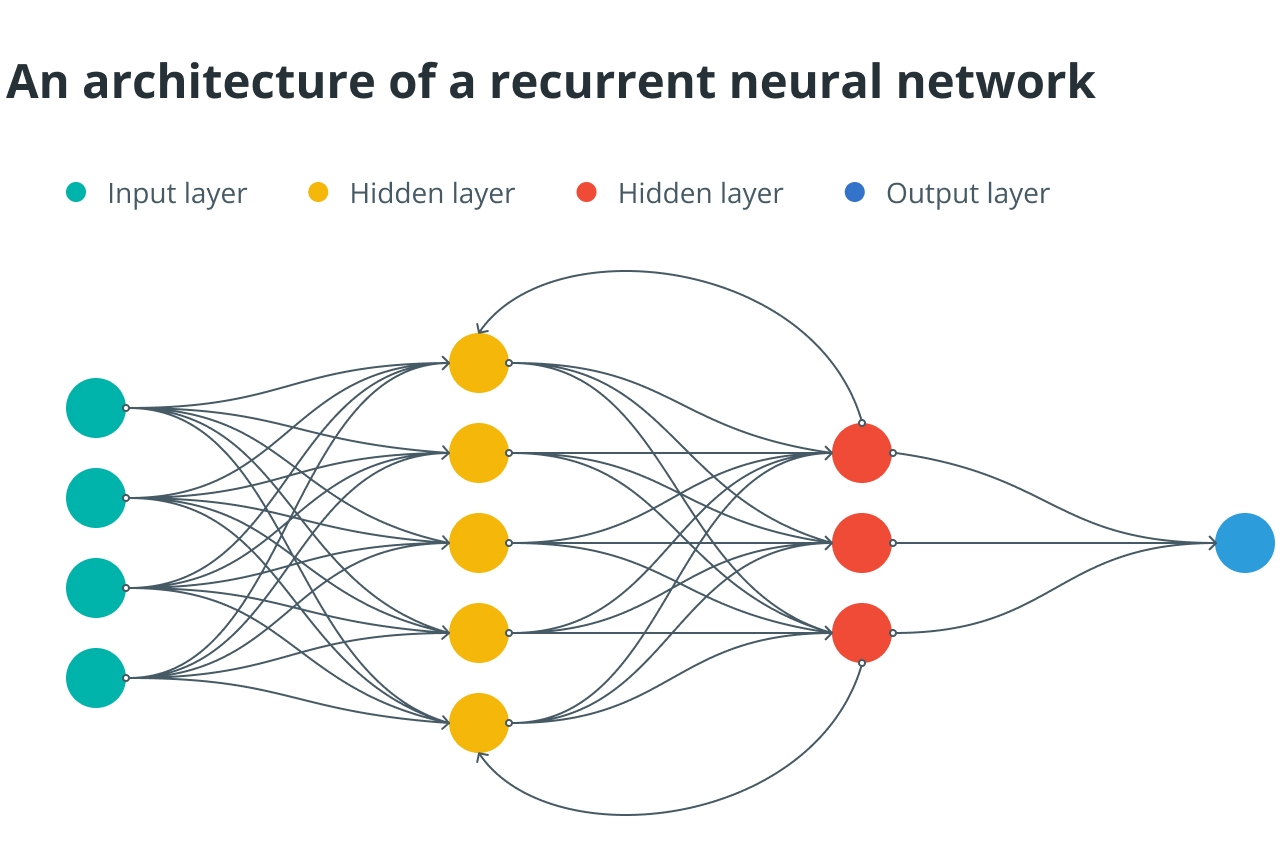
Jaringan saraf berulang (RNNs) adalah jenis jaringan saraf yang dapat memproses data berurutan dengan melacak konteks input sebelumnya. Jaringan saraf berulang dapat menangani input dengan panjang yang bervariasi dan menghasilkan output yang bergantung pada input sebelumnya, tidak seperti jaringan saraf umpan maju biasa yang hanya memproses data input dalam urutan tetap.
Misalnya RNN dapat digunakan dalam aktivitas NLP seperti pembuatan teks atau terjemahan bahasa. Jaringan saraf berulang dapat dilatih pada pasangan kalimat dalam dua bahasa berbeda untuk belajar menerjemahkan di antara keduanya.
RNN memproses kalimat satu per satu, menghasilkan kalimat keluaran tergantung pada kalimat masukan dan keluaran sebelumnya pada setiap langkah. RNN dapat menghasilkan terjemahan yang benar bahkan untuk teks kompleks karena terus melacak masukan dan keluaran sebelumnya.
Jaringan konvolusional penuh
Jaringan konvolusional penuh (FCN) adalah jenis arsitektur jaringan saraf yang biasa digunakan dalam tugas visi komputer seperti segmentasi gambar, deteksi objek, dan klasifikasi gambar. FCN dapat dilatih end-to-end menggunakan backpropagation untuk mengkategorikan atau mengelompokkan gambar.
Backpropagation adalah algoritma pelatihan yang menghitung gradien fungsi kerugian sehubungan dengan bobot jaringan saraf. Kemampuan model pembelajaran mesin untuk memprediksi keluaran yang diantisipasi untuk masukan tertentu diukur dengan fungsi kerugian.
FCN semata-mata didasarkan pada lapisan konvolusional karena mereka tidak memiliki lapisan yang terhubung sepenuhnya, menjadikannya lebih mudah beradaptasi dan efisien secara komputasi daripada jaringan saraf konvolusional konvensional. Jaringan yang menerima gambar input dan menampilkan lokasi dan klasifikasi objek di dalam gambar adalah contoh FCN.
Jaringan transformator spasial
Jaringan transformator spasial (STN) digunakan dalam tugas visi komputer untuk meningkatkan invarian spasial dari fitur yang dipelajari oleh jaringan. Kemampuan jaringan saraf untuk mengenali pola atau objek dalam gambar terlepas dari lokasi geografis, orientasi, atau skalanya dikenal sebagai invarian spasial.
Jaringan yang menerapkan transformasi spasial yang dipelajari ke gambar input sebelum memprosesnya lebih lanjut adalah contoh STN. Transformasi dapat digunakan untuk menyelaraskan objek di dalam gambar, mengoreksi distorsi perspektif, atau melakukan perubahan spasial lainnya untuk meningkatkan kinerja jaringan pada pekerjaan tertentu.
Transformasi mengacu pada operasi apa pun yang mengubah gambar dengan cara tertentu seperti memutar, menskalakan, atau memotong. Alignment mengacu pada proses memastikan bahwa objek dalam gambar terpusat, berorientasi atau diposisikan dengan cara yang konsisten dan bermakna.
Ketika objek dalam gambar tampak miring atau berubah bentuk karena sudut atau jarak pengambilan gambar terjadi distorsi perspektif. Menerapkan beberapa transformasi matematis pada gambar seperti transformasi affine yang dapat digunakan untuk memperbaiki distorsi perspektif. Transformasi Affine mempertahankan garis paralel dan rasio jarak antar titik untuk mengoreksi distorsi perspektif atau perubahan spasial lainnya dalam gambar.
Perubahan spasial mengacu pada setiap modifikasi pada struktur spasial suatu gambar seperti membalik, memutar, atau menerjemahkan gambar. Perubahan ini dapat menambah data pelatihan atau mengatasi tantangan khusus dalam tugas seperti pencahayaan, kontras, atau variasi latar belakang.
Apa keuntungan dari Jaringan Saraf Konvolusional CNN?
CNN lebih disukai dalam tugas visi komputer karena kelebihannya termasuk invarian terjemahan, berbagi parameter, representasi hierarkis, ketahanan terhadap perubahan, dan pelatihan ujung ke ujung. Jaringan saraf konvolusional ini memiliki beberapa keunggulan yang menjadikannya pilihan yang menarik untuk berbagai tugas visi komputer.
Salah satu keunggulan utama mereka adalah invarian terjemahan fitur CNN yang memungkinkan mereka mengenali objek dalam gambar terlepas dari posisinya. Lapisan convolutional digunakan untuk mencapai hal ini dengan menerapkan filter ke gambar input penuh sehingga jaringan dapat mempelajari fitur yang terjemahan-invarian.
Penggunaan berbagi parameter di mana kumpulan parameter yang sama dibagikan di semua area gambar input adalah manfaat lain dari CNN. Akibatnya jaringan memiliki lebih sedikit parameter dan dapat menggeneralisasi data baru dengan lebih baik yang sangat penting saat bekerja dengan kumpulan data yang besar.
CNN juga dapat mempelajari representasi hierarkis dari gambar input dengan lapisan atas mempelajari fitur yang lebih rumit seperti potongan dan bentuk objek, sedangkan lapisan bawah mempelajari elemen yang lebih sederhana seperti tepi dan tekstur. Untuk tugas-tugas yang menantang seperti deteksi objek dan segmentasi, model hierarkis ini memungkinkan jaringan untuk mempelajari karakteristik di banyak level abstraksi.
CNN cocok untuk aplikasi dunia nyata karena tahan terhadap perubahan pencahayaan, warna, dan distorsi kecil pada gambar input. Akhirnya jaringan saraf convolutional dapat dilatih end-to-end, memungkinkan penurunan gradien untuk secara bersamaan mengoptimalkan semua parameter jaringan untuk kinerja dan konvergensi yang lebih cepat. Penurunan gradien adalah algoritme pengoptimalan yang digunakan untuk menyesuaikan parameter model secara iteratif dengan meminimalkan fungsi kerugian ke arah gradien negatif.
Apa kerugian dari Jaringan Saraf Konvolusional CNN?
CNN memiliki kekurangan seperti waktu pelatihan yang lama, kebutuhan akan kumpulan data berlabel besar dan kerentanan terhadap overfitting. Kompleksitas jaringan juga dapat memengaruhi kinerja. Namun CNN tetap menjadi alat yang banyak digunakan dan efektif dalam visi komputer termasuk deteksi dan segmentasi objek meskipun ada keterbatasan dalam tugas yang membutuhkan pengetahuan kontekstual seperti NLP.
Jaringan saraf convolutional ini memiliki beberapa kelemahan yang dapat mempersulit penggunaannya dalam beberapa aplikasi pembelajaran mesin Misalnya pelatihan CNN dapat memakan waktu cukup lama terutama untuk kumpulan data besar karena CNN mahal secara komputasi. Selain itu membuat arsitektur CNN dapat menjadi tantangan dan memerlukan pemahaman menyeluruh tentang ide dasar jaringan saraf tiruan.
Kelemahan lainnya adalah CNN membutuhkan banyak data berlabel untuk berlatih secara efektif. Ini bisa menjadi kendala serius dalam situasi dengan sedikit data yang tersedia. CNN juga tidak selalu berhasil dalam tugas yang membutuhkan lebih banyak pengetahuan kontekstual seperti NLP, meskipun mereka cukup baik dalam tugas pengenalan gambar.
Jumlah dan jenis lapisan yang digunakan dalam desain CNN dapat memengaruhi kinerja. Misalnya menambahkan lebih banyak lapisan dapat meningkatkan akurasi tetapi meningkatkan kompleksitas jaringan dan biaya komputasi pada saat yang bersamaan. Arsitektur CNN pembelajaran mendalam juga rentan terhadap overfitting yang terjadi ketika jaringan terlalu terspesialisasi pada data pelatihan dan berkinerja buruk pada data baru yang tidak terlatih.
Terlepas dari kekurangan ini, CNN masih merupakan alat yang banyak digunakan dan sangat efektif untuk pembelajaran mendalam dan algoritma pembelajaran mesin di bidang jaringan saraf tiruan termasuk segmentasi, deteksi objek, dan pengenalan gambar. Konon CNN akan tetap menjadi pemain kunci dalam visi komputer.